2. Accessing Text Corpora and Lexical Resources
Mohamad's interest is in Programming (Mobile, Web, Database and Machine Learning). He is studying at the Center For Artificial Intelligence Technology (CAIT), Universiti Kebangsaan Malaysia (UKM).
1 Accessing Text Corpora
A text corpus is a large body of text. Many corpora are designed to contain a careful balance of material in one or more genres.
1.1 Gutenberg Corpus
import nltk
nltk.download('gutenberg')
nltk.corpus.gutenberg.fileids()
output:

opening a text
# opening a text
emma = nltk.corpus.gutenberg.words('austen-emma.txt')
len(emma)
shorter codes
# alternative, shorter way
from nltk.corpus import gutenberg
emma = gutenberg.words('austen-emma.txt')
len(emma)
display other information about each text; average word length, average sentence length, and the number of times each vocabulary item appears in the text on average (lexical diversity score).
# using loop control structure to display other information about each text
import nltk
nltk.download('punkt')
for fileid in gutenberg.fileids():
num_chars = len(gutenberg.raw(fileid))
num_words = len(gutenberg.words(fileid))
num_sents = len(gutenberg.sents(fileid))
num_vocab = len(set(w.lower() for w in gutenberg.words(fileid)))
print(round(num_chars/num_words), round(num_words/num_sents), round(num_words/num_vocab), fileid)
output:

Using sents() function to divide the text up into its sentences, where each sentence is a list of words
# Using sents() function to divide the text up into its sentences,
# where each sentence is a list of words
macbeth_sentences = gutenberg.sents('shakespeare-macbeth.txt')
print(macbeth_sentences)
print(macbeth_sentences[1116])
longest_len = max(len(s) for s in macbeth_sentences)
print( longest_len )
output:

1.2 Web and Chat Text
Web text
# download webtext
import nltk
nltk.download('webtext')
# open web corpus
from nltk.corpus import webtext
for fileid in webtext.fileids():
print(fileid, webtext.raw(fileid)[:65], '...')
Chat text
# download nps_chat corpus
import nltk
nltk.download('nps_chat')
# open nps_chat
from nltk.corpus import nps_chat
chatroom = nps_chat.posts('10-19-20s_706posts.xml')
chatroom[123]
['i', 'do', "n't", 'want', 'hot', 'pics', 'of', 'a', 'female', ',',
'I', 'can', 'look', 'in', 'a', 'mirror', '.']
1.3 Brown Corpus
# download brown corpus
import nltk
nltk.download('brown')
# open brown corpus
from nltk.corpus import brown
print( brown.categories() )
print( brown.words(categories='news') )
print( brown.words(fileids=['cg22']) )
print( brown.sents(categories=['news', 'editorial', 'reviews']) )
1.4 Reuters Corpus
# download reuters corpus
import nltk
nltk.download('reuters')
# open reuter corpus
from nltk.corpus import reuters
print( reuters.fileids() )
print( reuters.categories() )
# view detailed information
print( reuters.categories('training/9865') )
print( reuters.categories(['training/9865', 'training/9880']) )
print( reuters.fileids('barley') )
print( reuters.fileids(['barley', 'corn']) )
1.5 Inaugural Address Corpus
# download inaugural corpus
import nltk
nltk.download('inaugural')
# open corpus
from nltk.corpus import inaugural
print( inaugural.fileids() )
print( [fileid[:4] for fileid in inaugural.fileids()] )
# get conditional frequency distribution
cfd = nltk.ConditionalFreqDist(
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target))
cfd.plot()
output:

1.6 Annotated Text Corpora
https://www.nltk.org/howto/corpus.html
1.7 Corpora in Other Languages
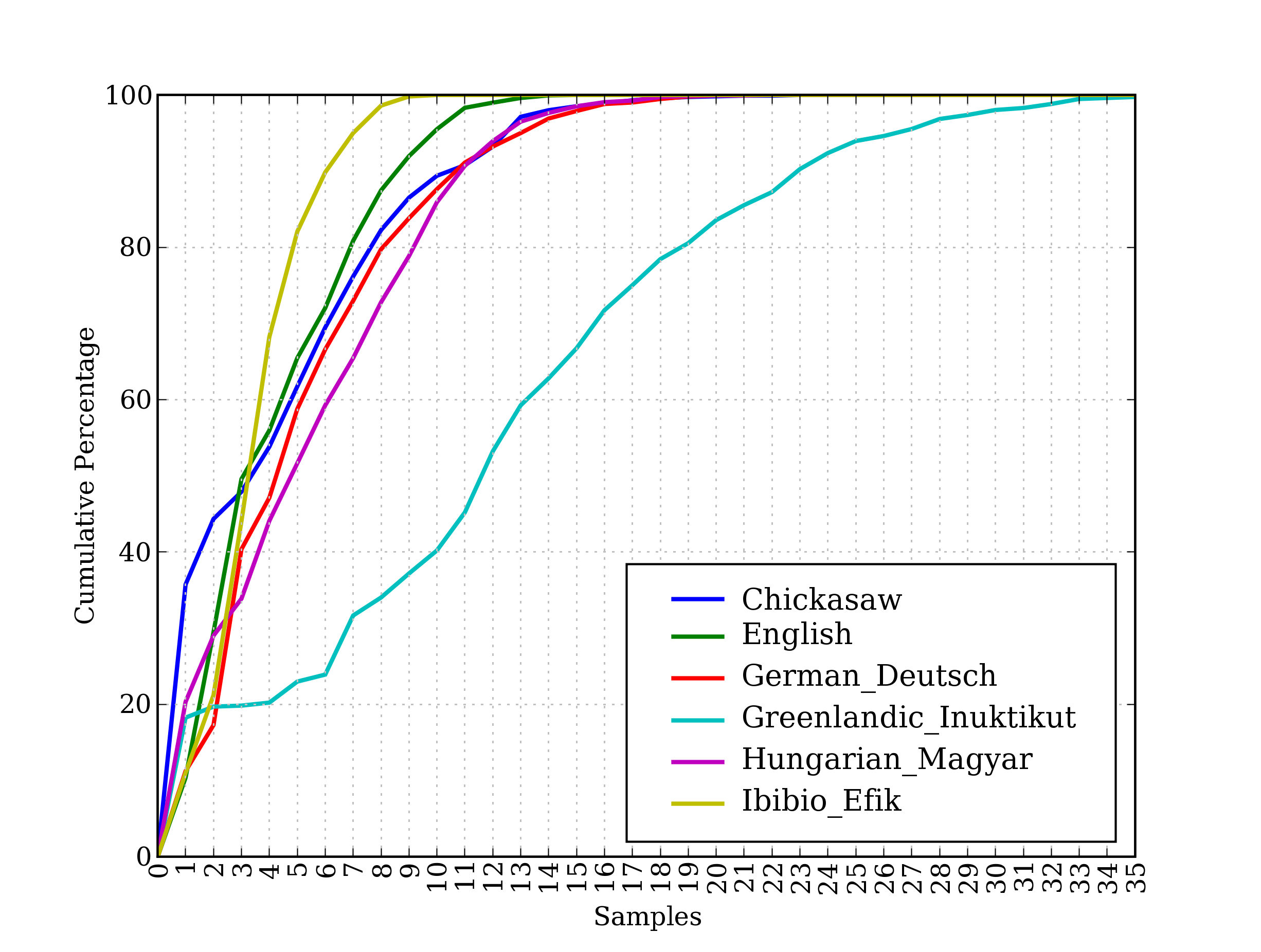
from nltk.corpus import udhr
languages = ['Chickasaw', 'English', 'German_Deutsch',
'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
cfd17 = nltk.ConditionalFreqDist(
(lang, len(word))
for lang in languages
for word in udhr.words(lang + '-Latin1'))
cfd17.plot(cumulative=True)
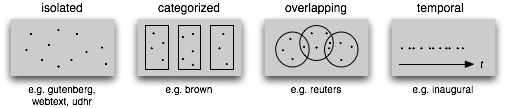
1.8 Text Corpus Structure
The simplest kind lacks any structure: it is just a collection of texts.
Often, texts are grouped into categories that might correspond to genre, source, author, language, etc.
Sometimes these categories overlap, notably in the case of topical categories as a text can be relevant to more than one topic.
Occasionally, text collections have temporal structure, news collections being the most common example.
NLTK Corpus and Corpus Reader:
Each corpus module defines one or more “corpus reader functions”, which can be used to read documents from that corpus.
corpus reader: https://www.nltk.org/api/nltk.corpus.reader.html
NLTK Corpus-related functions and their descriptions:
fileids() - the files of the corpus
fileids([categories]) - the files of the corpus corresponding to these categories
categories() - the categories of the corpus
categories([fileids]) - the categories of the corpus corresponding to these files
raw() - the raw content of the corpus
raw(fileids=[f1,f2,f3]) - the raw content of the specified files
raw(categories=[c1,c2]) - the raw content of the specified categories
words() - the words of the whole corpus
words(fileids=[f1,f2,f3]) - the words of the specified fileids
words(categories=[c1,c2]) - the words of the specified categories
sents() - the sentences of the whole corpus
sents(fileids=[f1,f2,f3]) - the sentences of the specified fileids
sents(categories=[c1,c2]) - the sentences of the specified categories
abspath(fileid) - the location of the given file on disk
encoding(fileid) - the encoding of the file (if known)
open(fileid) - open a stream for reading the given corpus file root if the path to the root of locally installed corpus
readme() - the contents of the README file of the corpus
Some of the Corpora and Corpus Samples Distributed with NLTK:
(refer https://www.nltk.org/api/nltk.corpus.reader.html)
| Corpus | Compiler | Contents |
| Brown Corpus | Francis, Kucera | 15 genres, 1.15M words, tagged, categorized |
| CESS Treebanks | CLiC-UB | 1M words, tagged and parsed (Catalan, Spanish) |
| Chat-80 Data Files | Pereira & Warren | World Geographic Database |
| CMU Pronouncing Dictionary | CMU | 127k entries |
| CoNLL 2000 Chunking Data | CoNLL | 270k words, tagged and chunked |
| CoNLL 2002 Named Entity | CoNLL | 700k words, pos- and named-entity-tagged (Dutch, Spanish) |
| CoNLL 2007 Dependency Treebanks (sel) | CoNLL | 150k words, dependency parsed (Basque, Catalan) |
| Dependency Treebank | Narad | Dependency parsed version of Penn Treebank sample |
| FrameNet | Fillmore, Baker et al | 10k word senses, 170k manually annotated sentences |
| Floresta Treebank | Diana Santos et al | 9k sentences, tagged and parsed (Portuguese) |
| Gazetteer Lists | Various | Lists of cities and countries |
| Genesis Corpus | Misc web sources | 6 texts, 200k words, 6 languages |
| Gutenberg (selections) | Hart, Newby, et al | 18 texts, 2M words |
| Inaugural Address Corpus | CSpan | US Presidential Inaugural Addresses (1789-present) |
| Indian POS-Tagged Corpus | Kumaran et al | 60k words, tagged (Bangla, Hindi, Marathi, Telugu) |
| MacMorpho Corpus | NILC, USP, Brazil | 1M words, tagged (Brazilian Portuguese) |
| Movie Reviews | Pang, Lee | 2k movie reviews with sentiment polarity classification |
| Names Corpus | Kantrowitz, Ross | 8k male and female names |
| NIST 1999 Info Extr (selections) | Garofolo | 63k words, newswire and named-entity SGML markup |
| Nombank | Meyers | 115k propositions, 1400 noun frames |
| NPS Chat Corpus | Forsyth, Martell | 10k IM chat posts, POS-tagged and dialogue-act tagged |
| Open Multilingual WordNet | Bond et al | 15 languages, aligned to English WordNet |
| PP Attachment Corpus | Ratnaparkhi | 28k prepositional phrases, tagged as noun or verb modifiers |
| Proposition Bank | Palmer | 113k propositions, 3300 verb frames |
| Question Classification | Li, Roth | 6k questions, categorized |
| Reuters Corpus | Reuters | 1.3M words, 10k news documents, categorized |
| Roget's Thesaurus | Project Gutenberg | 200k words, formatted text |
| RTE Textual Entailment | Dagan et al | 8k sentence pairs, categorized |
| SEMCOR | Rus, Mihalcea | 880k words, part-of-speech and sense tagged |
| Senseval 2 Corpus | Pedersen | 600k words, part-of-speech and sense tagged |
| SentiWordNet | Esuli, Sebastiani | sentiment scores for 145k WordNet synonym sets |
| Shakespeare texts (selections) | Bosak | 8 books in XML format |
| State of the Union Corpus | CSPAN | 485k words, formatted text |
| Stopwords Corpus | Porter et al | 2,400 stopwords for 11 languages |
| Swadesh Corpus | Wiktionary | comparative wordlists in 24 languages |
| Switchboard Corpus (selections) | LDC | 36 phonecalls, transcribed, parsed |
| Univ Decl of Human Rights | United Nations | 480k words, 300+ languages |
| Penn Treebank (selections) | LDC | 40k words, tagged and parsed |
| TIMIT Corpus (selections) | NIST/LDC | audio files and transcripts for 16 speakers |
| VerbNet 2.1 | Palmer et al | 5k verbs, hierarchically organized, linked to WordNet |
| Wordlist Corpus | OpenOffice.org et al | 960k words and 20k affixes for 8 languages |
| WordNet 3.0 (English) | Miller, Fellbaum | 145k synonym sets |
Sample usage for WordNet
https://www.nltk.org/howto/wordnet.html
Importing nltk wordnet corpus reader into codes:
# WordNet is just another NLTK corpus reader, and can be imported like this
from nltk.corpus import wordnet
# For more compact code, we recommend:
from nltk.corpus import wordnet as wn
Before using nltk wordnet corpus reader, download the corpus data:
import nltk
nltk.download('wordnet')
Look up a word using synsets():
wn.synsets('dog')

Sample usage for SentiWordNet
https://www.nltk.org/howto/sentiwordnet.html
Importing nltk wordnet corpus reader into codes:
# SentiWordNet can be imported like this:
from nltk.corpus import sentiwordnet as swn
Before using nltk sentiwordnet corpus reader, download the corpus data:
import nltk
nltk.download('sentiwordnet')
Example uses of SentiWordNet:
# Example uses of SentiSynsets
breakdown = swn.senti_synset('breakdown.n.03')
print(breakdown)
print('*****')
print ('pos score:', breakdown.pos_score())
print ()
print ('neg score:', breakdown.neg_score())
print ()
print ('obj score:', breakdown.obj_score())

Example uses of SentiWordNet lookups:
# Example uses of SentiSynset Lookups
print ('list swn senti synsets: ' , list(swn.senti_synsets('slow')))
print ()
print ('swn senti synsets for happy: ' , list(swn.senti_synsets('happy', 'a')) )
print ()
print ('swn senti synsets for angry: ' , list(swn.senti_synsets('angry', 'a')) )
print ()

(additional)using pandas:
import pandas as pd
df_senti_synsets=pd.DataFrame([[a.synset.name(),a.pos_score(),a.neg_score(),a.obj_score()] for a in list_senti_synset])
df_senti_synsets.rename(columns = {0:'synset',1:'pos',2:'neg',3:'obj'}, inplace = True)
df_senti_synsets.loc[df_senti_synsets.obj<0.5]

1.9 Loading your own Corpus
2 Conditional Frequency Distributions
2.1 Conditions and Events
text = ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said',]
pairs = [('news', 'The'), ('news', 'Fulton'), ('news', 'County'),]
2.2 Counting Words by Genre
2.3 Plotting and Tabulating Distributions
2.4 Generating Random Text with Bigrams
3 More Python: Reusing Code
3.1 Creating Programs with a Text Editor
3.2 Functions
3.3 Modules
4 Lexical Resources
A lexicon, or lexical resource, is a collection of words and/or phrases along with associated information such as part of speech and sense definitions.
Lexical resources are secondary to texts, and are usually created and enriched with the help of texts.
For example,
if we have defined a text my_text,
then vocab = sorted(set(my_text)) builds the vocabulary of my_text,
while word_freq = FreqDist(my_text) counts the frequency of each word in the text.
Both of vocab and word_freq are simple lexical resources.
Similarly, a concordance gives us information about word usage that might help in the preparation of a dictionary.
Standard terminology for lexicons :
A lexical entry consists of a headword (also known as a lemma) along with additional information such as the part of speech and the sense definition.
Two distinct words having the same spelling are called homonyms.

4.1 Wordlist Corpora
4.2 A Pronouncing Dictionary
4.3 Comparative Wordlists
4.4 Shoebox and Toolbox Lexicons
5 WordNet
5.1 Senses and Synonyms
5.2 The WordNet Hierarchy
5.3 More Lexical Relations
5.4 Semantic Similarity
6 Summary
A text corpus is a large, structured collection of texts. NLTK comes with many corpora, e.g., the Brown Corpus, nltk.corpus.brown.
Some text corpora are categorized, e.g., by genre or topic; sometimes the categories of a corpus overlap each other.
A conditional frequency distribution is a collection of frequency distributions, each one for a different condition. They can be used for counting word frequencies, given a context or a genre.
Python programs more than a few lines long should be entered using a text editor, saved to a file with a .py extension, and accessed using an import statement.
Python functions permit you to associate a name with a particular block of code, and re-use that code as often as necessary.
Some functions, known as "methods", are associated with an object and we give the object name followed by a period followed by the function, like this: x.funct(y), e.g., word.isalpha().
To find out about some variable v, type help(v) in the Python interactive interpreter to read the help entry for this kind of object.
WordNet is a semantically-oriented dictionary of English, consisting of synonym sets — or synsets — and organized into a network.
Some functions are not available by default, but must be accessed using Python's import statement.
Colab Notebook:
https://colab.research.google.com/drive/12OWlfeZW9fIWNp7Ob8S8OPPqHgc8gUd5?usp=sharing

